
Microsoft registra falhas no Azure dias após o apagão da AWS
Falhas no Azure afetaram plataformas como Office 365, Xbox e Minecraft, revelando a vulnerabilidade das grandes infraestruturas de nuvem e a dependência global desses serviços.

O mundo digital está cada vez mais interconectado, e as falhas nos serviços de nuvem têm um impacto significativo em milhões de usuários e empresas em nível global. Recentemente, ocorreu uma importante interrupção no Microsoft Azure, o serviço de computação em nuvem da Microsoft, que evidenciou a dependência crítica de muitos setores nessas plataformas para suas operações diárias. Essa queda aconteceu logo após um incidente semelhante na Amazon Web Services (AWS), ressaltando as vulnerabilidades que ainda existem na gestão da infraestrutura de nuvem em larga escala.
Os incidentes na plataforma Azure afetaram uma ampla gama de serviços ligados ao ecossistema da Microsoft, como Minecraft, Office 365 e Xbox, gerando interrupções na conectividade e acesso a ferramentas essenciais para usuários individuais e empresas. A dependência do Azure para manter infraestruturas digitais operantes ficou ainda mais clara quando usuários de todo o mundo começaram a relatar falhas em plataformas como Downdetector, poucos minutos após o início do problema.
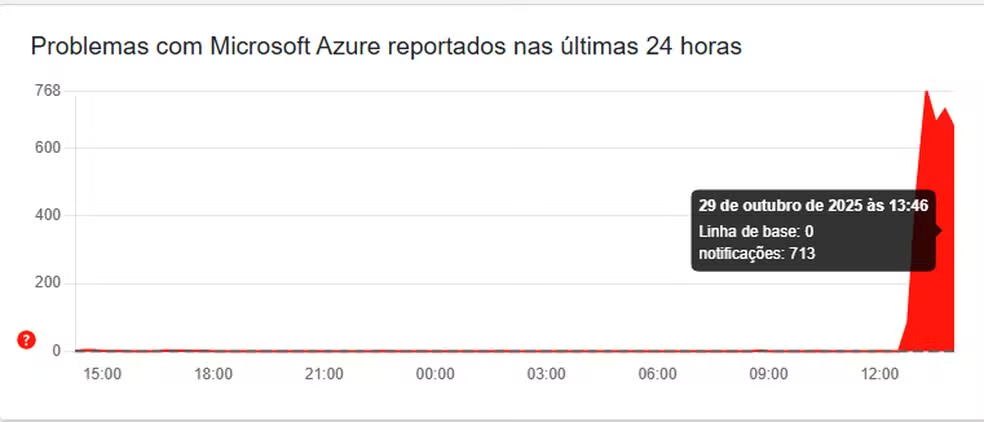
Qual foi a origem do problema na Microsoft Azure?
Conforme a própria Microsoft, o problema começou devido a uma “mudança de configuração involuntária” no Azure Front Door, uma das camadas críticas que gerenciam o acesso e o tráfego aos serviços na nuvem. Esse erro não apenas afetou o funcionamento de aplicativos e serviços, mas também evidenciou a complexidade e os desafios de administrar infraestruturas em tamanha escala.
- A equipe técnica do Azure reagiu rapidamente, trabalhando para reconfigurar o sistema e recomendando o uso de ferramentas alternativas, como PowerShell, para que os clientes mantivessem acesso aos seus recursos durante a solução do incidente.
- O evento destaca como pequenos ajustes podem impactar globalmente, mostrando a importância de evitar falhas humanas na administração dessas plataformas.
Quais foram as estratégias de recuperação após a falha?
Para mitigar os efeitos do problema, a Microsoft implementou protocolos de failover, buscando redirecionar o tráfego por rotas mais estáveis. Essas estratégias são fundamentais para minimizar interrupções e garantir que serviços essenciais retornem ao ar o mais rápido possível.
- A experiência ressaltou a importância de estratégias robustas de contingência, com a própria Microsoft recomendando a implementação do Azure Traffic Manager para manter a disponibilidade dos serviços em situações críticas.
- Com essas medidas, empresas podem reduzir consideravelmente o tempo de indisponibilidade diante de falhas na nuvem.
AWS and Azure are currently down
— SciTech Era (@SciTechera) October 29, 2025
Affecting a large portion of online infrastructure. Nearly 52% of the internet relies on these two platforms, so many services are experiencing widespread issues.
Crypto apps, payment gateways, Ai models, even corporate dashboards are freezing.… pic.twitter.com/zh45K8U8Vc
Leia também: Esses celulares não poderão mais usar o Whatsapp a partir de novembro
Quais medidas podem prevenir futuras quedas semelhantes?
Incidentes como esse mostram a necessidade de aprimoramento constante nos sistemas de gestão da nuvem para evitar problemas semelhantes. A transparência da Microsoft ao relatar e corrigir rapidamente a situação é crucial para manter a confiança dos usuários.
- Empresas que dependem desses serviços devem desenvolver sólidos planos de contingência para emergências.
- A implementação de protocolos de failover e alternativas de acesso deve ser uma prioridade, garantindo resiliência diante de situações imprevisíveis na infraestrutura digital.
Os comentários não representam a opinião do site; a responsabilidade pelo conteúdo postado é do autor da mensagem.
Comentários (0)